
Why Only Using SKAdNetwork for Campaign Optimization Is Insufficient
As clarity starts to form around how MMPs and ad networks plan to work with SKAdNetwork, we’d like to spend some time discussing in more detail how we can use Apple’s SKAdNetwork for performance marketing and why it’s critical to consider more than just this set of data for campaign optimization.
What does it mean to only use SKAdNetwork?
The key piece of data within SKAdNetwork to help with campaign optimization is “ConversionValue” (conversion value). This piece of data gives some indication of post-install performance and is sent to the ad network by the app and reported at the campaign level. This conversion value can be defined using early revenue, engagement, and retention events, or—most optimally—predicted LTV (pLTV).
An advertiser can decide to optimize their campaigns solely by using the conversion value, making bid and budget decisions based on the number of conversion values in any single campaign or channel, effectively normalizing the performance across channels and campaigns. In practice, this would mean that one conversion value from Facebook would be valued the same as one on, say, Unity Ads.
For the remainder of this article, we’ll assume that the final conversion value is sent to the ad network within the first 24 hours after install, as per Facebook’s definition. Therefore, using only SKAdNetwork data to optimize your mobile marketing campaigns means you:
- Only optimize campaigns toward D0 ROAS or other D0 KPIs
- Can’t update campaign ROAS based on updated cohort data
When using SKAdNetwork to optimize campaigns, it’s possible to use only the conversion value to determine the allocation of bids and budgets. In this case, if you wanted to consider the long-term performance of your advertising campaigns, you wouldn’t model the predicted revenue that campaign drove, but only model the long-term ROAS of users/cohorts as a function of conversion value by building a model that maps conversion value to LTV (i.e. if we know that).
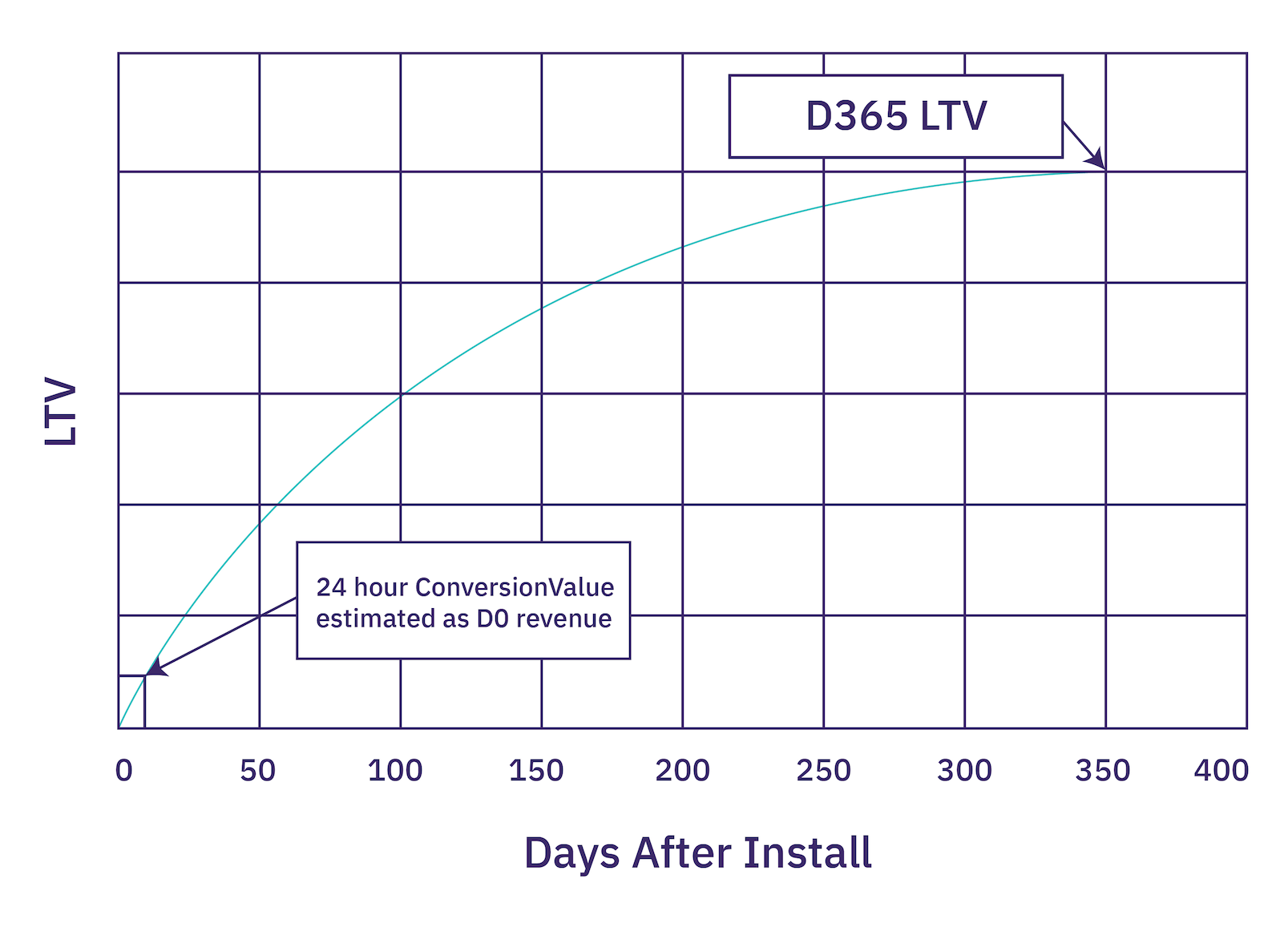
The above chart shows how an advertiser would attempt to map conversion value to LTV, first by mapping conversion value to D0 revenue, and then by extrapolating D0 revenue to D365 LTV (if this is your target).
There are two significant inefficiencies when extrapolating conversion value to LTV:
- Approximating D0 revenue from ConversionValue is challenging, especially if the user can’t generate revenue within the first 24 hours (e.g. an app that monetizes through subscriptions with a free trial). The best approximation for D0 revenue is a range or cumulative view—e.g. $0-$5 or $10+.
- Using your D0 revenue approximation to project D365 revenue is also challenging as it doesn’t adequately reflect proper variations in revenue. It assumes all campaigns and channels have exactly the same behavior. This will penalize high ROAS campaigns/channels and benefit low ROAS campaigns/channels to the detriment of the portfolio returns.
The conversion value, whether based on early revenue, engagement, or predicted LTV (pLTV) acts as an early signal for ad networks to optimize against. Ideally, we’d like to update the predicted ROAS (pROAS) for campaigns or channels based on updated user behavior, which would give us a more informed view of the historical performance of campaigns. For example, if we see that user LTV has changed after the first 24 hours, it’s prudent to update our understanding of the campaign pROAS, even though that may be several days in the past.
When using only conversion value, however, to optimize SKAdNetwork campaigns, there’s no consideration for the underlying users that make up these campaigns. This means that once the conversion value is received from the ad network (via an MMP) and the D0 KPI is calculated, there’s no way to then update this prediction based on updated knowledge of each campaign’s underlying user behavior.
The core challenge with only using SKAdNetwork data to optimize campaigns is that we don’t know what the underlying user behavior of a campaign looks like. If we don’t have this data, we can’t determine if users or campaigns with the same conversion value actually behave the same. We should then try to understand what the underlying behavior of users is in the campaign to solve this problem. When working on this problem, we’re not trying to create a one-to-one mapping of install-to-campaign, that would be impossible based on how SKAdNetwork works and against the spirit of Apple’s privacy initiatives. It’s useful, however, to use statistical methods to create probabilities for which campaign each install might have come from.
What other data sets are available?
We’ve discussed why using SKAdNetwork data has such limited application, but we do have several other important data sets available to us to help model predicted campaign revenue.
Those data sets are:
1. Anonymized (user-level) behavioral data: This is a user’s in-app engagement and revenue data all reported against an anonymous user ID. As a user engages with an app, this will continue to be an abundant dataset encompassing all users’ behavior throughout their lifetime of using that app.
This is a critical data set to enable us to:
- Predict LTV for longer horizons than D1
- Update historical campaign predictions based on updated user behavior
2. Ad network-reported metrics: Mainly campaign spend, clicks, and impressions.
3. Deterministic attribution from MMPs: Where we know the attribution of a user, this data reduces the amount of statistical modeling we need to do to predict which users are coming from which campaigns. We can’t use this data as the basis for a model as this data isn’t a representative sample but useful nonetheless.
When we incorporate the SKAdNetwork data, the Anonymized (user-level) behavioral data and the Ad network-reported metrics, we can model the underlying user behavior of a campaign. This is key to solving the two core problems raised by only using SKAdNetwork postbacks that we highlighted earlier. Leveraging the anonymous user-level behavioral data, we can probabilistically attribute installs back to campaigns because we know the user-level behavior and can define the conversion value based on this user in-app engagement data. We can then map back to conversion value data from the SKAdNetwork postbacks.
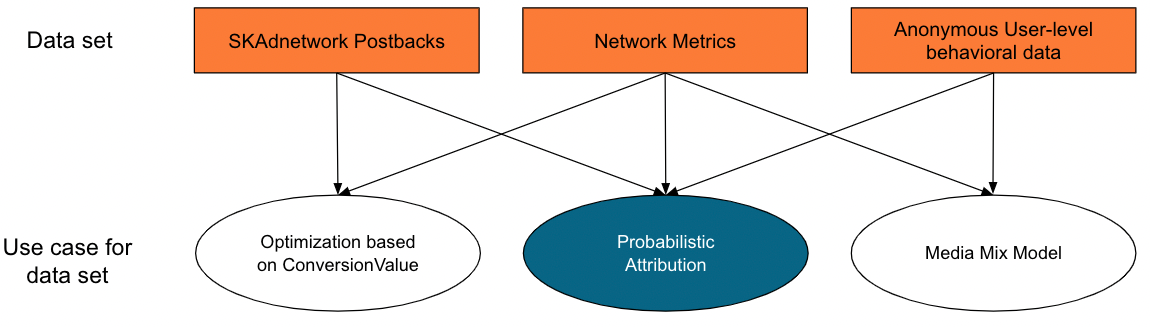
Shown in the diagram above – the probabilistic attribution solution (we should note here that this is not a so called “fingerprinting” approach) is the only use case for the data which leverages all three datasets to their full potential. Measuring performance using only SKAdNetwork conversion values, as explained earlier, ignores the richer set of user data, resulting in a stale rather than a dynamic picture of campaign performance.
Another potential solution is to use media mix models (MMMs), which model high-level KPIs (e.g. total daily installs, total cohorted revenue) as a function of more granular inputs, such as campaign or channel budget allocation. In practice, MMMs have a high degree of uncertainty, as it’s hard to get enough signals to truly measure the incrementality of individual channels or campaigns, especially when these effects are changing over time and data quickly becomes outdated. This approach would also ignore the bottom-up measurement capability that SKAdNetwork provides.
Probabilistic attribution bridges the gap and provides advertisers with the most holistic measurement solution given the data that is available.
Learn more about AlgoLift by Vungle’s measurement solutions that solve for Apple’s privacy changes by contacting us below.